本文基于 jemalloc-5.2.1 分支分析 jemalloc 内存管理的代码,以及 memory profiling 相关的实现。
jemalloc 结构
从高向低的介绍几个关键的结构体,以及他们的关联关系。
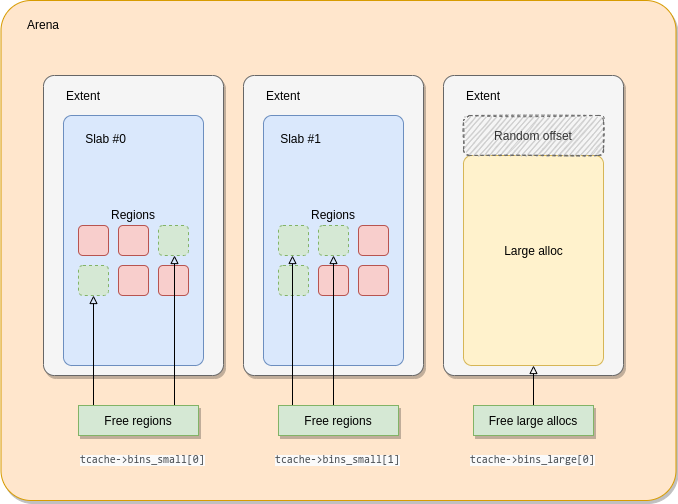

arena
主要的管理 allocation 结构,一般几个线程共用一个 arena。
extent
一大块内存的管理结构,该内存通过 mmap 向 OS 申请,其中的成员 e_addr 字段指向真正管理的内存,数个页大小。一个 extent 可以当做是一次 large 类型的分配,也可以拆分成多个 small 的内存块。
region
region 就是 small 的小内存块,一个 extent 会被划分为数个同样大小的 region。
slab
一个 extent 会拆分成多个同样大小的内存,slab 的是基于 extent 的。
bin
存储同样大小内存块指针的结构。
tsd
thread specific data,存储 tcache, arena 等线程关联的结构。
tcache
thread cache 的缩写,存储线程刚被释放的内存块,用于快速分配。
size class
(可以忽略这段)
这里介绍 jemalloc 中 size class 的约定,在 include/jemalloc/internal/sc.h 进行了详细的注释注解,一个 size class 代表一种大小的分配类型。
首先忽略最小的几组 small size class。定义 size class group,每个 size class group 涵盖 (base, base * 2] 大小的内存分配,每个 group 里有 4 个 size class,定义为 SC_NGROUP,则其之间的差值为 delta = base/SC_NGROUP。也就是包含下面 4 个 size class:
| |
LG_QUANTUM 定义了分配的最小 alignment,这里 LG 代表取对数,jemalloc 将对齐大小定义为 16,所以 LG_QUANTUM 就是 4。但是为了避免浪费内存,还定义了 SC_LG_TINY_MIN 意为最小的分配大小,默认最小分配大小是 8,所以这值为 3。所以定义了一组 tiny size class: (0, 8]。
另外对于 1 << LG_QUANTUM,也就是 16 没法自成一个 size class group,因为如果把 16~32 之间再拆分成 4 组的话,就没法满足最小的 alignment。所以最初的几组定义为 pseudo group:
| |
也就是
| |
总结:
| |
另外大于 page size * group size 的大小的分配,被认为是 large size classes,默认情况下也就是大于 4K * 4 = 16K 的为 large size classes。
分配与释放
small size 分配
首先会获取 tsd结构,使用 tsd中的 tcache结构的 tcache 尝试申请。这种 thread-specific 的数据使用 pthread_setspecific 和 pthread_getspecific 函数设置和获取。
tcache 中使用 cache_bin 存储了多种 sized class 的内存块,比方说 tcache.bins_small[0] 用来存储 8 bytes 大小的内存块指针。如果顺利的话,直接就在这里分配出去了。
tcache 如果没发服务分配的话,会使用 arena 进行分配,arena 用来管理 extent,也就是从系统 mmap 来的数个页大小的大内存块。如果 extent 被拆分用于 small size 内存的分配,那么这个 extent 也被称为 slab。
arena 使用 bin 来管理各个 sized class 的 extent,如果 tcache 没有了,就会从相应的 bin 里面取来,拆分成 region 填充 tcache,然后用来分配内存。bin 里面也有多种级别的 extent,会依次尝试 bin.slabcur,bin.slabs_nonfull,然后尝试 arena 级别的 extent 缓存:extents_dirty, extents_muzzy, extents_retained。
如果 arena->bins[x] 里也没有 extent 了,那将会从 OS 处申请。
释放
释放其实就是上面反过来的过程。
性能调优
重要数据来源 jemalloc stats
lg_page 逻辑页面大小
使用编译参数 -with-lg-page 调整 page size,以提高性能。
arena 个数
线程过多会导致 arena 锁竞争,适当的提高 arena 的数目可以减少。
dirty decay, muzzy decay
通过这俩参数配置 extents 归还给系统的速度
oversize_threshold
超过这个临界值,会使用单独的 arena 分配,没有 tcache,一些情况下会导致 page fault 比较高。
profiling 相关
使用 jemalloc 的 memory profiling 需要在编译 configure 时添加参数 --enable-prof,这会在 jemalloc 中添加 profiling 相关的代码。profiling 的开启有两道开关,第一道是 opt_prof,标识是否启用 profiling 相关的代码;第二道开关是 prof_active ,设置了这个参数才开始记录,可以在程序运行中通过 malloc_ctl 设置开启,也可以在运行前通过 MALLOC_CONF 环境变量设置,这样启动时就打开了。
jemalloc 的内存分析也是基于采样的,与采样相关的一个关键参数是 lg_prof_sample,意为采样频率的指数,默认值是 19,也就是每分配 2**19 = 512KB 采样一次,实际上采样的间隔也不是固定的,通过一个算法使得平均值为 512KB。这样的做的是为了避免固定周期的采样带来的倾斜。
jemalloc 的采样机制,使得每 bytes 具有相同的概率被采样到;而不是根据分配的次数,根据分配的次数来采样会导致数据倾斜到小内存的采样。虽然根据 bytes 会让 sample 倾斜到大内存分配,但我们就是内存大小的 profile,所以这就是合理的。具体的机制可以参照这个文档 jemalloc profiling internals。
采样的过程是这样的,每个 tsd 结构维护一个 bytes_until_sample 字段,在 fast path 分配时也会进行检查和更新,当小于 0 时就到慢路径处理分配。经过 je_malloc() -> malloc_default() -> imalloc() -> imalloc_body() 的一串调用来到这里,会调用 prof_alloc_prep() 进行 prof 的准备,这个函数里面会再次调用 prof_sample_accum_update() -> prof_sample_check() 确定 bytes_until_sample 是否满足要求(这里我感觉 bytes_until_sample 可能会被减了两次,通过 je_malloc 里快路径减一次,如果小于 0,或者没有从 tcache 分配成功,均会进入 malloc_default(),然后会被减第二次,没搞明白),不满足则返回值为 1 的指针;满足的话则会准备完整的 prof_tctx_t 结构,通过 prof_backtrace() 准备栈回溯。
这里根据不同的编译选项会使用不同的方式来进行栈回溯,
libgcc,libunwind,intrinsic gcc,在 master 上还添加了新的frame pointer方式,这里有一些 MR 的讨论。通过讨论可以知道,虽然 fp 有较好的性能,但 Meta 目前还是以libunwind为默认,以避免在一些外部的闭源库里产生回溯不全的问题。
栈回溯好后,会使用 prof_lookup() 函数查找是否有相同栈回溯的线程局部缓存 prof_tctx_t 和全局 prof_gctx_t 结构,没有的话,均会进行创建,确保每一种栈回溯在全局的哈希表 bt2gctx 和线程局部里的 tsd_t->prof_tdata->bt2tctx 里都有维护。
他们都会互相联系起来,prof_gctx_t 里面有一个红黑树成员 tctxs 指向各个线程里具有相同 bt 的 tctx;tctx 里也有个结构 gctx 指向全局的;还有个全局变量的哈希表 bt2gctx 指向所有的 gctx。
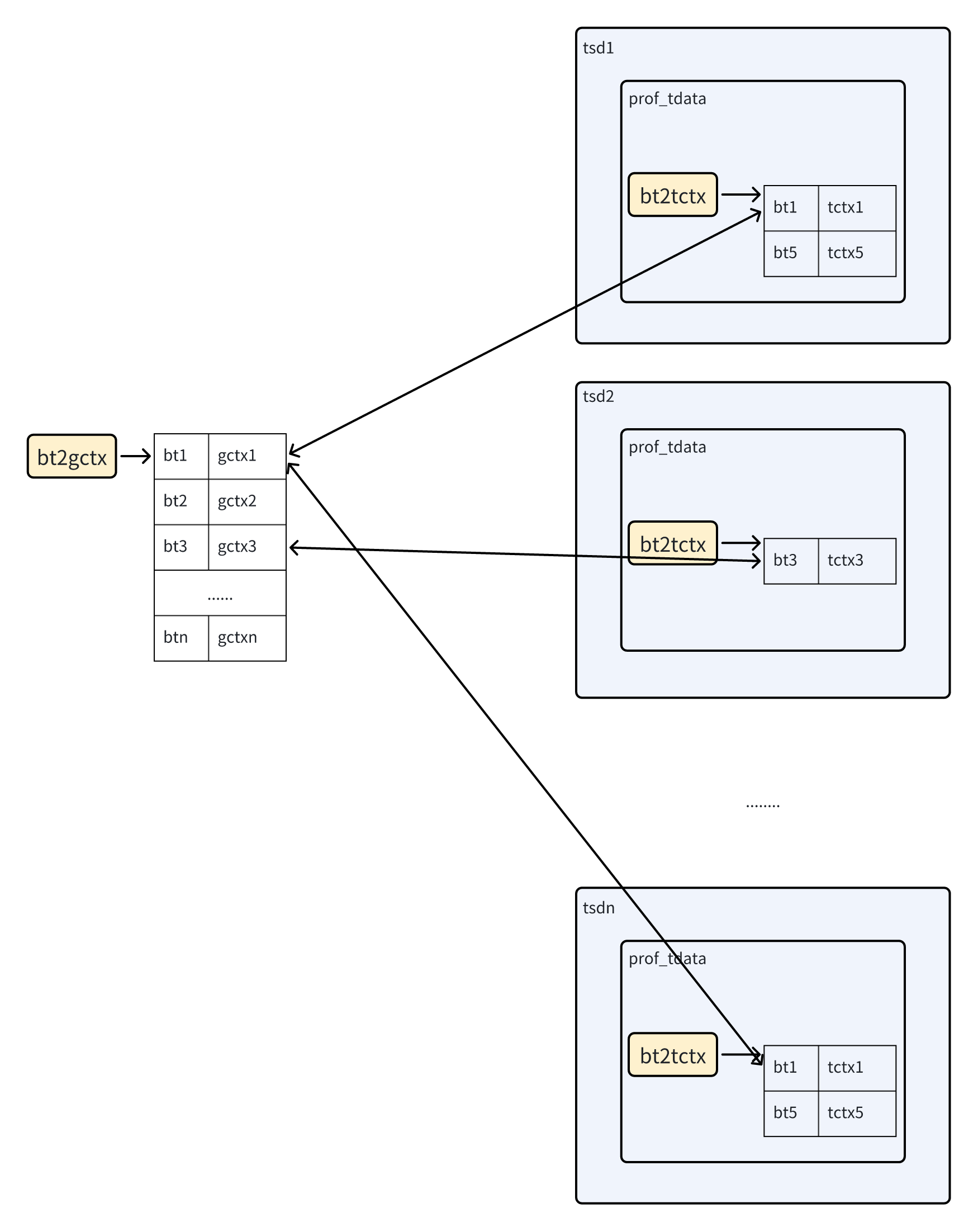
有点扯远了,prof_lookup() 返回了 tctx 后,如果值为 1 说明本次不采样,走正常路径分配内存;而如果大于 1 则认为本次采样,走 imalloc_sample() 函数里进行分配,该函数会将 small size class 的内存 promote 到 min large size class(也就是 1 << (LG_PAGE + SC_LG_NGROUP) 的大小,默认就是 16KB)。为什么呢,为了方便的保存本次采样的上下文 tctx,正好在这个大小里,会直接关联 extent_t,通过 extent_t 结构里的字段保存 profiling 上下文。还可以很方便的根据指针通过 radix tree 找到这个该块地址对应的 extent_t 结构。每次在 free 比较大的内存时,都会进行该块内存是否被 sampled 的检查,如果是则删去相关的统计信息。
总结
jemalloc 设计了多种级别的缓存,来减少分配的延迟,不论是在用户态分配,还是向内核态申请。强大性能的背后,也是复杂化的代价。