目前 Linux 标准发行版中使用的堆分配器是 glibc 中的堆分配器:ptmalloc2。ptmalloc2 主要是通过 malloc/free 函数来分配和释放内存块。
需要注意的是,在内存分配与使用的过程中,Linux 有这样的一个基本内存管理思想,只有当真正访问一个地址的时候,系统才会建立虚拟页面与物理页面的映射关系。
基本操作
malloc
malloc(size_t n)
- 当 n=0 时,返回当前系统允许的堆的最小内存块。
- 当 n 为负数时,由于在大多数系统上,size_t 是无符号数(这一点非常重要),所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。
free
free(void *p)
- 当 p 为空指针时,函数不执行任何操作。
- 当 p 已经被释放之后,再次释放会出现乱七八糟的效果,这其实就是
double free。 - 除了被禁用 (mallopt) 的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便于减小程序所使用的内存空间。
背后的系统调用
这些函数背后的系统调用主要是 (s)brk 函数以及 mmap, munmap 函数。

初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启 ASLR,两者的具体位置会有所不同
- 不开启 ASLR 保护时,start_brk 以及 brk 会指向 data/bss 段的结尾。
- 开启 ASLR 保护时,start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
具体效果如下图
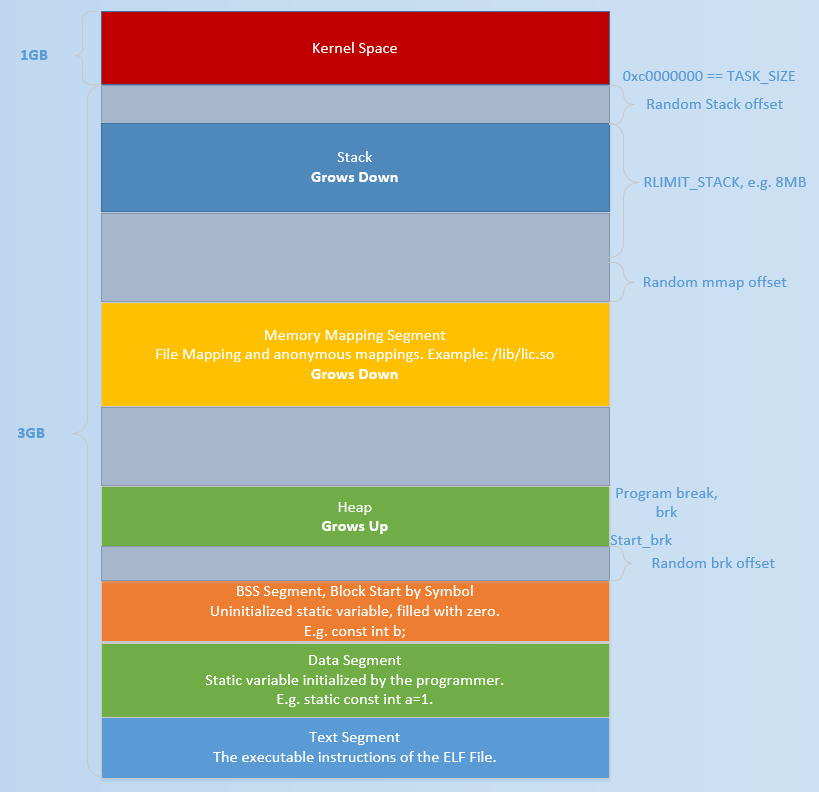
brk,sbrk
| |
mmap,munmap
| |
| |
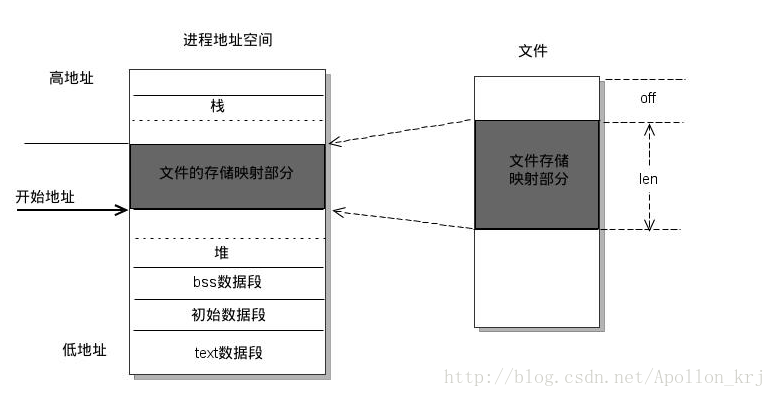
Glibc malloc
GNU C标准库的malloc实现源自于ptmalloc(pthreads malloc),ptmalloc源于dlmalloc(Doug Lea malloc)。
glibc malloc通常使用两种方式分配内存,具体使用哪种方式由请求的大小和某些参数决定。一种是使用连续大段区域进行管理以提高分配效率减少浪费,通常堆区域只有一个,但glibc实现使用了多个堆区域,用来优化多线程的性能,每个区域内部称为一个arena;另一种是使用mmap,通过在请求大量内存时使用,大量指远大于一个页的大小1。
INTERNAL_SIZE_T,SIZE_SZ,MALLOC_ALIGN_MASK
| |
一般来说,size_t 在 64 位中是 64 位无符号整数,32 位中是 32 位无符号整数。
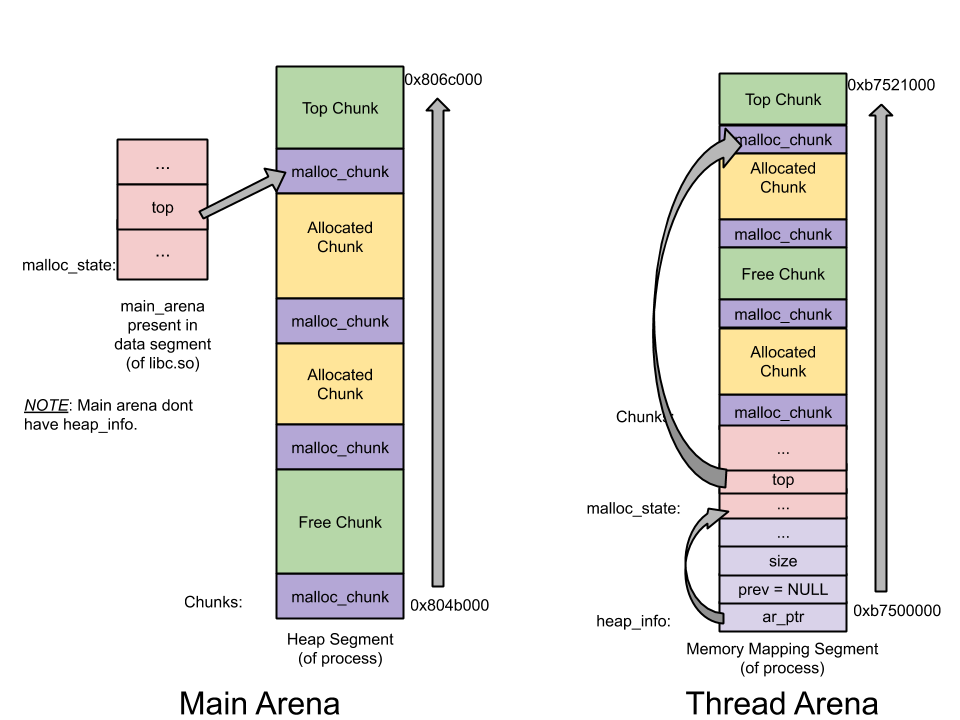
Arena
Arena分为main arena和thread arena。
glibc中通过增加arena来优化对线程的支持,但并非每个线程都有一个arena,因为代价高意义不大。arena的个数由cpu核心个数所限制,限制如下。这个限制是对于thread arena。
| |
例子:如果一个多线程应用(4 threads—1 main thread + 3 user thread)运行在一个单核的32位系统上。thread arena的限制即为2 * number of cores(1) = 2。在这种情况下,glibc malloc将会确保arenas在几个线程中共享使用。
对于主线程调用malloc时,使用main arena分配空间
当线程1,2调用malloc时,创建两个新的arena分别供其使用。
当线程3调用malloc时,由于已经达到了arena的个数限制,将会复用已有的arenas(main arena,arena 1,arena 2)
- 遍历可用的arena,一旦存在可用arena,申请该arena的锁
- 如果锁定成功,返回该arena
- 如果没有找到可用的arena,阻塞直到有可用的arena。
当thread 3 调用 malloc 时(第二次了),分配器会尝试使用其上一次使用的 arena(也即,main arena),从而尽量提高缓存命中率。当 main arena 可用时就用,否则 thread 3 就一直阻塞,直至 main arena 空闲。因此现在 main arena 实际上是被 main thread 和 thread 3 所共享。
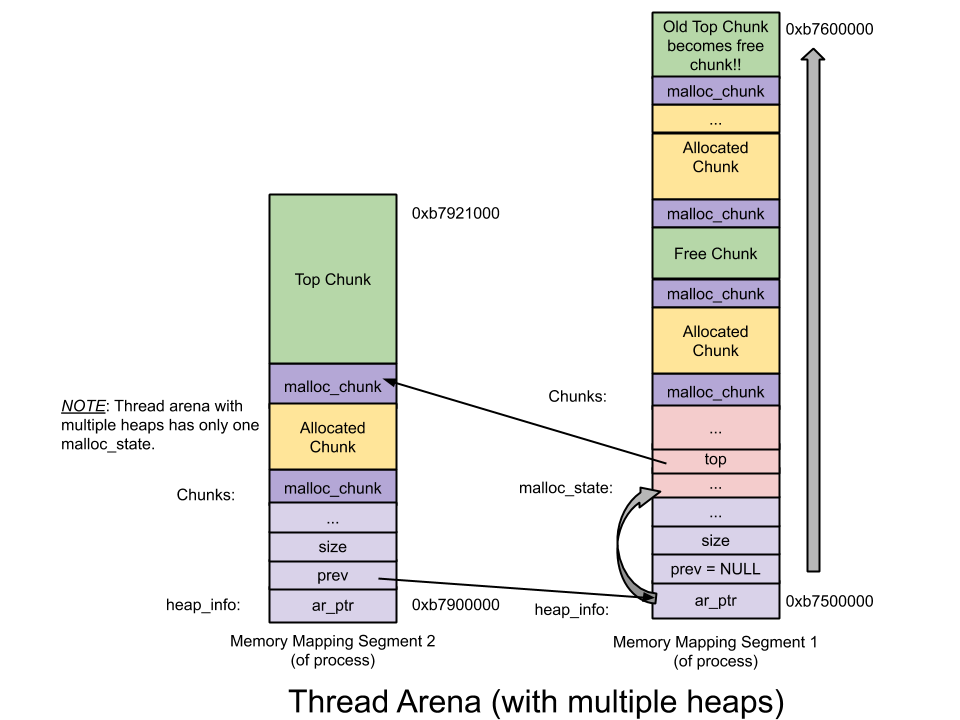
Multiple heaps
在「glibc malloc」中主要有 3 种数据结构:
malloc_state ——Arena header—— 一个 thread arena 可以维护多个堆,这些堆另外共享同一个 arena header。Arena header 描述的信息包括:bins、top chunk、last remainder chunk 等;由于 thread 的 arena 可能有多个,malloc state 结构会在最新申请的 arena 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38struct malloc_state { /* Serialize access. */ __libc_lock_define(, mutex); /* Flags (formerly in max_fast). */ int flags; /* Fastbins */ mfastbinptr fastbinsY[ NFASTBINS ]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[ NBINS * 2 - 2 ]; /* Bitmap of bins, help to speed up the process of determinating if a given bin is definitely empty.*/ unsigned int binmap[ BINMAPSIZE ]; /* Linked list, points to the next arena */ struct malloc_state *next; /* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ struct malloc_state *next_free; /* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ INTERNAL_SIZE_T attached_threads; /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };__libc_lock_define(, mutex);
该变量用于控制程序串行访问同一个分配区,当一个线程获取了分配区之后,其它线程要想访问该分配区,就必须等待该线程分配完成后才能够使用。
flags
flags 记录了分配区的一些标志,比如 bit0 记录了分配区是否有 fast bin chunk ,bit1 标识分配区是否能返回连续的虚拟地址空间。具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38/* FASTCHUNKS_BIT held in max_fast indicates that there are probably some fastbin chunks. It is set true on entering a chunk into any fastbin, and cleared only in malloc_consolidate. The truth value is inverted so that have_fastchunks will be true upon startup (since statics are zero-filled), simplifying initialization checks. */ #define FASTCHUNKS_BIT (1U) #define have_fastchunks(M) (((M)->flags & FASTCHUNKS_BIT) == 0) #define clear_fastchunks(M) catomic_or(&(M)->flags, FASTCHUNKS_BIT) #define set_fastchunks(M) catomic_and(&(M)->flags, ~FASTCHUNKS_BIT) /* NONCONTIGUOUS_BIT indicates that MORECORE does not return contiguous regions. Otherwise, contiguity is exploited in merging together, when possible, results from consecutive MORECORE calls. The initial value comes from MORECORE_CONTIGUOUS, but is changed dynamically if mmap is ever used as an sbrk substitute. */ #define NONCONTIGUOUS_BIT (2U) #define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0) #define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0) #define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT) #define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT) /* ARENA_CORRUPTION_BIT is set if a memory corruption was detected on the arena. Such an arena is no longer used to allocate chunks. Chunks allocated in that arena before detecting corruption are not freed. */ #define ARENA_CORRUPTION_BIT (4U) #define arena_is_corrupt(A) (((A)->flags & ARENA_CORRUPTION_BIT)) #define set_arena_corrupt(A) ((A)->flags |= ARENA_CORRUPTION_BIT)binmap
ptmalloc 用一个 bit 来标识某一个 bin 中是否包含空闲 chunk 。
heap_info ——Heap Header—— 一个 thread arena 可以维护多个堆。每个堆都有自己的堆 Header(注:也即头部元数据)。什么时候 Thread Arena 会维护多个堆呢? 一般情况下,每个 thread arena 都只维护一个堆,但是当这个堆的空间耗尽时,新的堆(而非连续内存区域)就会被
mmap到这个 aerna 里;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34#define HEAP_MIN_SIZE (32 * 1024) #ifndef HEAP_MAX_SIZE # ifdef DEFAULT_MMAP_THRESHOLD_MAX # define HEAP_MAX_SIZE (2 * DEFAULT_MMAP_THRESHOLD_MAX) # else # define HEAP_MAX_SIZE (1024 * 1024) /* must be a power of two */ # endif #endif /* HEAP_MIN_SIZE and HEAP_MAX_SIZE limit the size of mmap()ed heaps that are dynamically created for multi-threaded programs. The maximum size must be a power of two, for fast determination of which heap belongs to a chunk. It should be much larger than the mmap threshold, so that requests with a size just below that threshold can be fulfilled without creating too many heaps. */ /***************************************************************************/ /* A heap is a single contiguous memory region holding (coalesceable) malloc_chunks. It is allocated with mmap() and always starts at an address aligned to HEAP_MAX_SIZE. */ typedef struct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev; /* Previous heap. */ size_t size; /* Current size in bytes. */ size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;疑问 负数
malloc_chunk ——Chunk header—— 根据用户请求,每个堆被分为若干 chunk。每个 chunk 都有自己的 chunk header。
| |
注意:
- Main arena 无需维护多个堆,因此也无需 heap_info。当空间耗尽时,与 thread arena 不同,main arena 可以通过
sbrk拓展堆段,直至堆段「碰」到内存映射段;- 与 thread arena 不同,main arena 的 arena header 不是保存在通过
sbrk申请的堆段里,而是作为一个全局变量,可以在 libc.so 的数据段中找到
main arena和thread arena的图示(单堆)
thread arena图示(多堆)
Chunk
堆段中存在的 chunk 类型如下:
- Allocated chunk;
- Free chunk;
- Top chunk;
- Last Remainder chunk.
Allocated chunk

图中结构体内部各字段的含义依次为:
- prev_size:若前一个 chunk 可用,则此字段赋值为前一个 chunk 的大小;否则,此字段被用来存储前一个 chunk 的用户数据;
- size:此字段赋值本 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍,其最后三位包含标志信息:
- PREV_INUSE (P) – 置「1」表示前个 chunk 被分配;
- IS_MMAPPED (M) – 置「1」表示这个 chunk 是通过
mmap申请的(较大的内存); - NON_MAIN_ARENA (N) – 置「1」表示这个 chunk 属于一个 thread arena(mmapd’d memory)。
注意:
- malloc_chunk 中的其余结构成员,如 fd、 bk,如果该块已分配,则不会使用,用来存储用户数据;
- 用户请求的大小被转换为内部实际大小,因为需要额外空间存储 malloc_chunk,此外还需要考虑对齐。
Free chunk

图中结构体内部各字段的含义依次为:
- prev_size: 两个相邻 free chunk 会被合并成一个,因此该字段总是保存前一个 allocated chunk 的用户数据;
- size: 该字段保存本 free chunk 的大小;
- fd: Forward pointer —— 本字段指向同一 bin 中的下个 free chunk;
- bk: Backward pointer —— 本字段指向同一 bin 中的上个 free chunk
- fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,按照由大到小的顺序排列,不过其用于较大的 chunk(large chunk)。
Chunk相关的宏
chunk 与 mem 指针头部的转换
| |
最小的 chunk 大小
| |
最小申请的堆内存大小
用户最小申请的内存大小必须是 2 * SIZE_SZ 的最小整数倍。
注:就目前而看 MIN_CHUNK_SIZE 和 MINSIZE 大小是一致的,个人认为之所以要添加两个宏是为了方便以后修改 malloc_chunk 时方便一些。
| |
检查分配给用户的内存是否对齐
2 * SIZE_SZ 大小对齐。
| |
请求字节数判断
| |
将用户请求内存大小转为实际分配内存大小
由于 chunk 间复用,所以可以使用下一个 chunk 的 prev_size 字段。因此,这里只需要再添加 SIZE_SZ 大小即可以完全存储内容。
| |
Bins
「bins」 就是空闲列表数据结构。它们用以保存 free chunks。根据其中 chunk 的大小,bins 被分为如下几种类型:
- Fast bin;
- Unsorted bin;
- Small bin;
- Large bin.
保存这些 bins 的字段为:
fastbinsY: 这个数组用以保存 fast bins;
bins: 这个数组用于保存 unsorted bin、small bins 以及 large bins,共计可容纳 126 个,其中:
- Bin 1: unsorted bin;
- Bin 2 - 63: small bins;
- Bin 64 - 126: large bins.
malloc_state中的定义
| |
| 含义 | bin1 的 fd/bin2 的 prev_size | bin1 的 bk/bin2 的 size | bin2 的 fd/bin3 的 prev_size | bin2 的 bk/bin3 的 size |
|---|---|---|---|---|
| bin下标 | 0 | 1 | 2 | 3 |
bin的通用宏定义
| |
Fast bin
在所有的 bins 中,fast bins 路径享有最快的内存分配及释放速度。
默认情况下(32 位系统为例), fastbin 中默认支持最大的 chunk 的数据空间大小为 64 字节。但是其可以支持的 chunk 的数据空间最大为 80 字节。除此之外, fastbin 最多可以支持的 bin 的个数为 10 个,从数据空间为 8 字节开始一直到 80 字节(注意这里说的是数据空间大小,也即除去 prev_size 和 size 字段部分的大小)
fastbin的数量和CPU位数有关,但本质都是从小到大递增8或16字节(
SIZE_SZ * 2),直至其最大的大小80 * SIZE_SZ / 4。 最大size为80 * SIZE_SZ / 4,32位下是80字节,64位为160字节。[^ 4]
| |
ptmalloc 默认情况下会调用 set_max_fast(s) 将全局变量 global_max_fast 设置为 DEFAULT_MXFAST,也就是设置 fast bins 中 chunk 的最大值。当 MAX_FAST_SIZE 被设置为 0 时,系统就不会支持 fastbin 。
数量:10
- 每个 fast bin 都维护着一条 free chunk 的单链表,采用单链表是因为链表中所有 chunk 的大小相等,增删 chunk 发生在链表头部即可;—— LIFO
chunk 大小:8 字节递增
- fast bins 由一系列所维护 chunk 大小以 8 字节递增的 bins 组成。也即,
fast bin[0]维护大小为 16 字节的 chunk、fast bin[1]维护大小为 24 字节的 chunk。依此类推…… - 指定 fast bin 中所有 chunk 大小相同;
- fast bins 由一系列所维护 chunk 大小以 8 字节递增的 bins 组成。也即,
fastbin 索引
1 2 3 4 5 6 7#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[ idx ]) /* offset 2 to use otherwise unindexable first 2 bins */ // chunk size=2*size_sz*(2+idx) // 这里要减2,否则的话,前两个bin没有办法索引到。 #define fastbin_index(sz) \ ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)在 malloc 初始化过程中,最大的 fast bin 的大小被设置为 64 而非 80 字节。因为默认情况下只有大小 16 ~ 64 的 chunk 被归为 fast chunk 。
无需合并 —— 两个相邻 chunk 不会被合并(in_use 位一直设置)。虽然这可能会加剧内存碎片化,但也大大加速了内存释放的速度!
malloc(fast chunk)- 初始情况下 fast chunck 最大尺寸以及 fast bin 相应数据结构均未初始化,因此即使用户请求内存大小落在 fast chunk 相应区间,服务用户请求的也将是 small bin 路径而非 fast bin 路径;
- 初始化后,将在计算 fast bin 索引后检索相应 bin;
- 相应 bin 中被检索的第一个 chunk 将被摘除并返回给用户。
free(fast chunk)- 计算 fast bin 索引以索引相应 bin;
free掉的 chunk 将被添加到上述 bin 的头部。
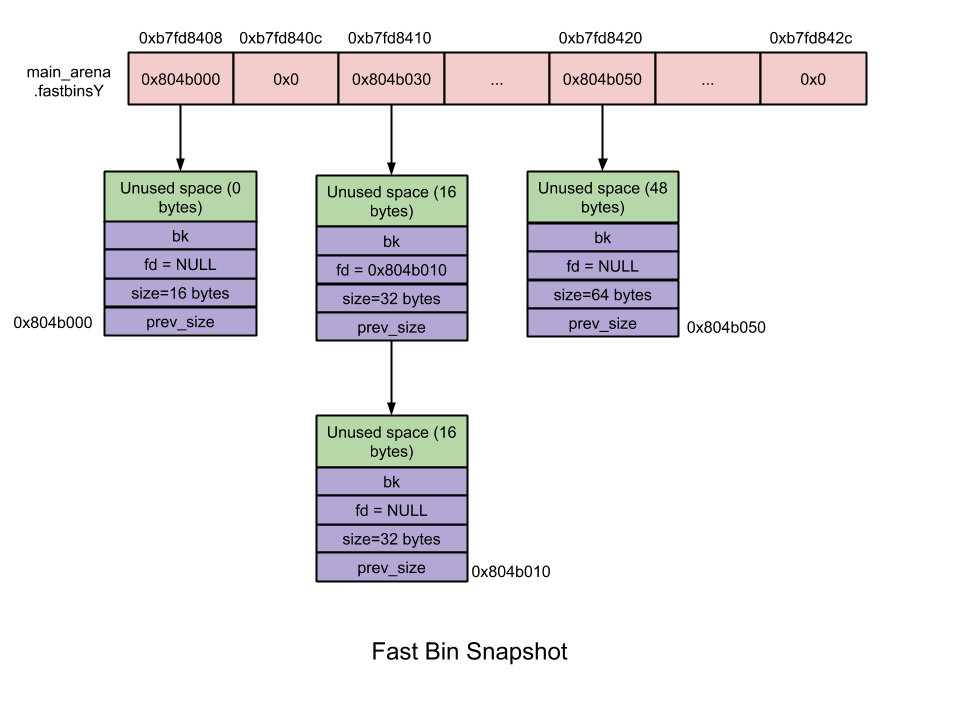
当释放的 chunk 与该 chunk 相邻的空闲 chunk 合并后的大小大于FASTBIN_CONSOLIDATION_THRESHOLD时,内存碎片可能比较多了,我们就需要把 fast bins 中的 chunk 都进行合并,以减少内存碎片对系统的影响。
| |
Unsorted bin
当 small chunk 和 large chunk 被 free 掉时,它们并非被添加到各自的 bin 中,而是被添加在 「unsorted bin」 中。这使得分配器可以重新使用最近 free 掉的 chunk,从而消除了寻找合适 bin 的时间开销,进而加速了内存分配及释放的效率。
unsorted bin 可以视为空闲 chunk 回归其所属 bin 之前的缓冲区。
| |
存疑 unsorted bin中的chunkNON_MAIN_ARENA 总是为0。2
数量:1
unsorted bin 包括一个用于保存 free chunk 的双向循环链表(又名 binlist);
chunk 大小:无限制,任何大小的 chunk 均可添加到这里。
来源
- 当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中。
- 释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。关于 top chunk 的解释,请参考下面的介绍。
此外,Unsorted Bin 在使用的过程中,采用的遍历顺序是 FIFO,头插尾取 。
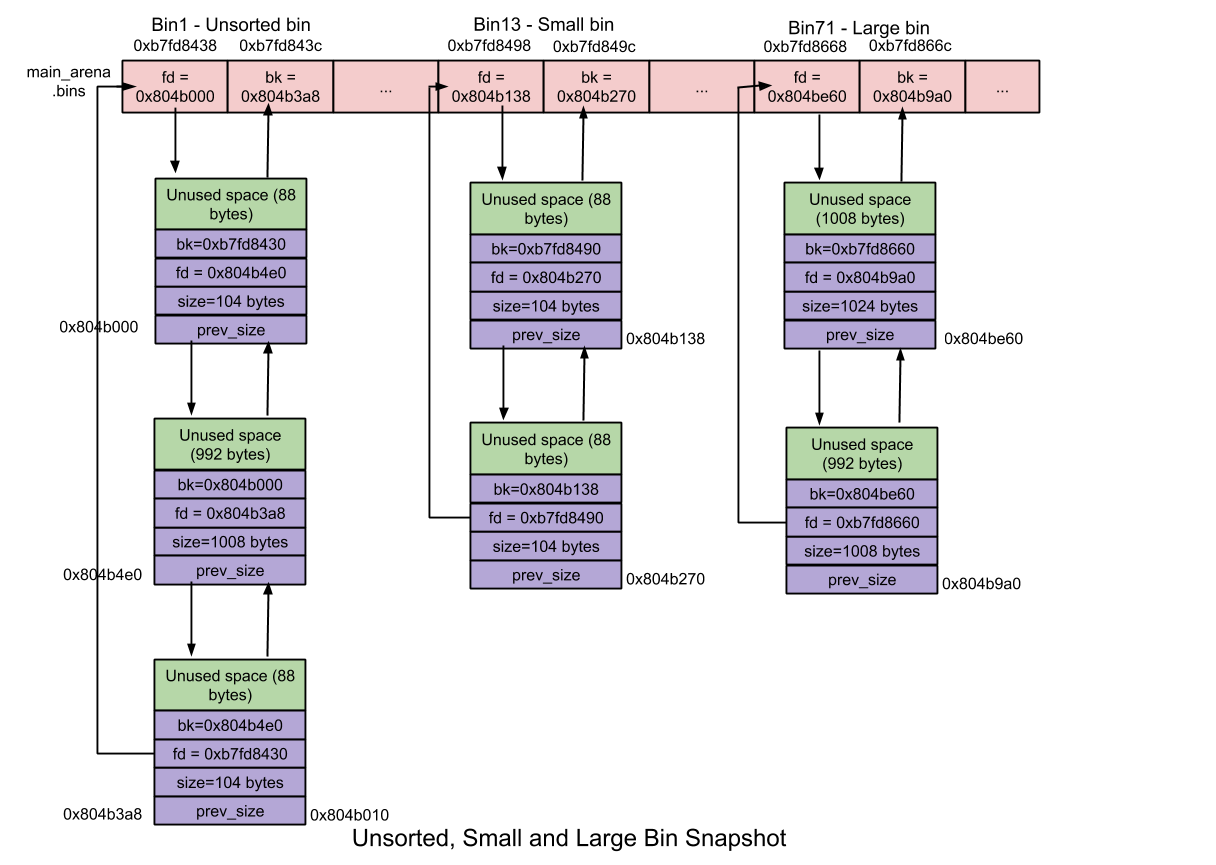
unsorted bin位置
| |
Small bin
在内存分配回收的速度上,small bin 比 large bin 更快。small bins 中每个 chunk 的大小与其所在的 bin 的 index 的关系为:chunk_size = 2 * SIZE_SZ *index,具体如下
| 下标(from 1) | SIZE_SZ=4(32 bit) | SIZE_SZ=8(64 bit) |
|---|---|---|
| 2 | 16 | 32 |
| 3 | 24 | 48 |
| 4 | 32 | 64 |
| 5 | 40 | 80 |
| x | 2*4*x | 2*8*x |
| 63 | 504 | 1008 |
数量:62
每个 small bin 都维护着一条 free chunk 的双向循环链表。采用双向链表的原因是,small bins 中的 chunk 可能会从链表中部摘除。这里新增项放在链表的头部位置,而从链表的尾部位置移除项。—— FIFO
chunk 大小:
- small bin 链表中的 chunk 大小相差的字节数为 2 个机器字长,即 32 位相差 8 字节,64 位相差 16 字节。
举例而言(32bit),
small bin[0](Bin 2)维护着大小为 16 字节的 chunks、small bin[1](Bin 3)维护着大小为 24 字节的 chunks ,依此类推……- 指定 small bin 中所有 chunk 大小均相同,因此无需排序;
合并 —— 相邻的 free chunk 将被合并,这减缓了内存碎片化,但是减慢了
free的速度;malloc(small chunk)- 初始情况下,small bins 都是 NULL,因此尽管用户请求 small chunk ,提供服务的将是 unsorted bin 路径而不是 small bin 路径;
- 第一次调用
malloc时,维护在 malloc_state 中的 small bins 和 large bins 将被初始化,它们都会指向自身以表示其为空; - 此后当 small bin 非空,相应的 bin 会摘除其中最后一个 chunk 并返回给用户;
free(small chunk)freechunk 的时候,检查其前后的 chunk 是否空闲,若是则合并,也即把它们从所属的链表中摘除并合并成一个新的 chunk,新 chunk 会添加在 unsorted bin 的前端。
smallbin相关宏
| |
Large bin
大小大于等于MIN_LARGE_SIZE 字节的 chunk 被称为「large chunk」,而保存 large chunks 的 bin 被称为 「large bin」。在内存分配回收的速度上,large bin 比 small bin 慢。
large bins 中的每一个 bin 都包含一定范围内的 chunk,其中的 chunk 按 fd_nextsize 指针的顺序从大到小排列。相同大小的 chunk 同样按照最近使用顺序排列。
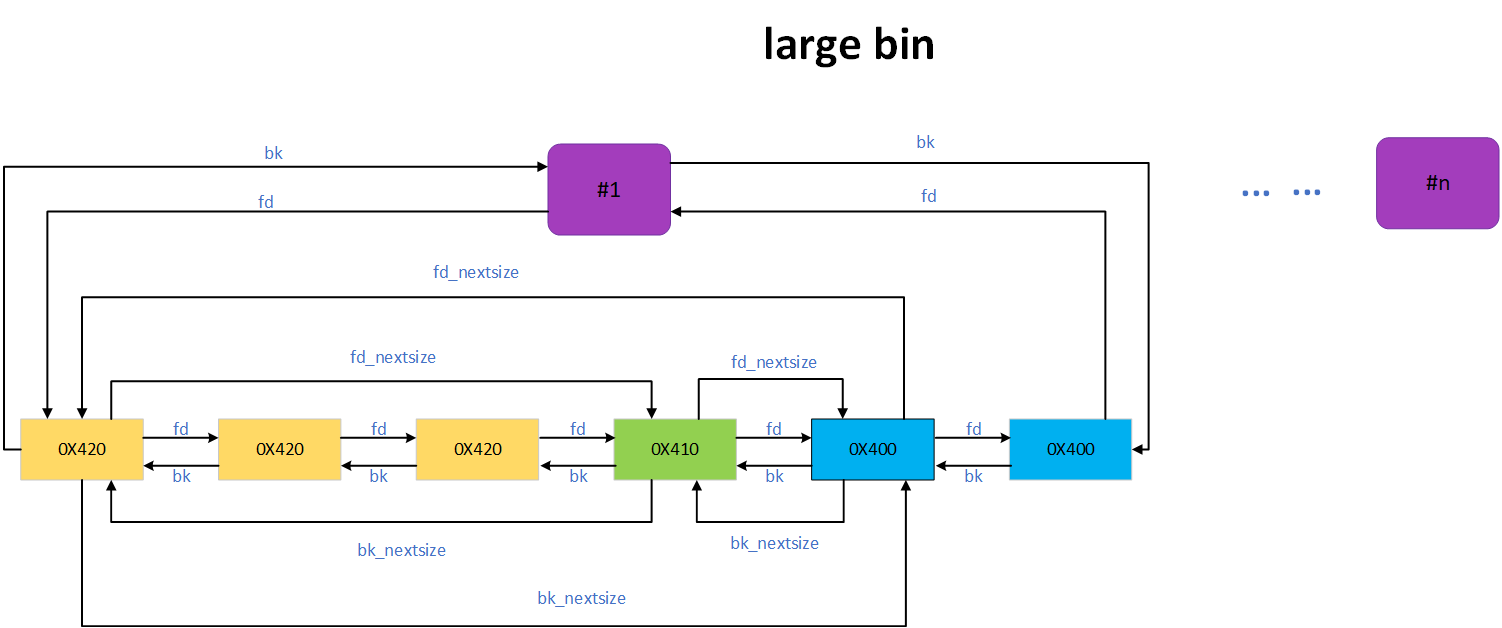
- 数量:63
- 每个 large bin 都维护着一条 free chunk 的双向循环链表。采用双向链表的原因是,large bins 中的 chunk 可能会从链表中的任意位置插入及删除。
- 这 63 个 bins
- 32 个 bins 所维护的 chunk 大小以 64B 递增,也即
large chunk[0](Bin 65) 维护着大小为 512B ~ 568B 的 chunk 、large chunk[1](Bin 66) 维护着大小为 576B ~ 632B 的 chunk,依此类推…… - 16 个 bins 所维护的 chunk 大小以 512 字节递增;
- 8 个 bins 所维护的 chunk 大小以 4096 字节递增;
- 4 个 bins 所维护的 chunk 大小以 32768 字节递增;
- 2 个 bins 所维护的 chunk 大小以 262144 字节递增;
- 1 个 bin 维护所有剩余 chunk 大小;
- 32 个 bins 所维护的 chunk 大小以 64B 递增,也即
- 不像 small bin ,large bin 中所有 chunk 大小不一定相同,各 chunk 大小递减保存。最大的 chunk 保存头端,而最小的 chunk 保存在尾端;
- 合并 —— 两个相邻的空闲 chunk 会被合并;
malloc(large chunk)- 初始情况下,large bin 都会是 NULL,因此尽管用户请求 large chunk ,提供服务的将是 next largetst bin 路径而不是 large bin 路径 。
- 第一次调用
malloc时,维护在 malloc_state 中的 small bin 和 large bin 将被初始化,它们都会指向自身以表示其为空; - 此后当 large bin 非空,如果相应 bin 中的最大 chunk 大小大于用户请求大小,分配器就从该 bin 顶端遍历到尾端,以找到一个大小最接近用户请求的 chunk。一旦找到,相应 chunk 就会被切分成两块:
- User chunk(用户请求大小)—— 返回给用户;
- Remainder chunk (剩余大小)—— 添加到 unsorted bin。
- 如果相应 bin 中的最大 chunk 大小小于用户请求大小,分配器就会扫描 binmaps,从而查找最小非空 bin。如果找到了这样的 bin,就从中选择合适的 chunk 并切割给用户;反之就使用 top chunk 响应用户请求。
free(large chunk)—— 类似于 small chunk 。
largebin相关宏
这里我们以 32 位平台下,第一个 large bin 的起始 chunk 大小为例,为 512 字节,那么 512»6 = 8,所以其下标为 56+8=64。
| |
Top bin
| |
一个 arena 中最顶部的 chunk 被称为「top chunk」。它不属于任何 bin 。当所有 bin 中都没有合适空闲内存时,就会使用 top chunk 来响应用户请求。
当 top chunk 的大小比用户请求的大小大的时候,top chunk 会分割为两个部分:
- User chunk,返回给用户;
- Remainder chunk,剩余部分,将成为新的 top chunk。
当 top chunk 的大小比用户请求的大小小的时候,top chunk 就通过 sbrk(main arena)或 mmap( thread arena)系统调用扩容。
需要注意的是,top chunk 的 prev_inuse 比特位始终为 1,否则其前面的 chunk 就会被合并到 top chunk 中。
Last remainder chunk
「last remainder chunk」即最后一次 small request 中因分割而得到的剩余部分,它有利于改进引用局部性,也即后续对 small chunk 的 malloc 请求可能最终被分配得彼此靠近。
那么 arena 中的若干 chunks,哪个有资格成为 last remainder chunk 呢?
当用户请求 small chunk 而无法从 small bin 和 unsorted bin 得到服务时,分配器就会通过扫描 binmaps 找到最小非空 bin。正如前文所提及的,如果这样的 bin 找到了,其中最合适的 chunk 就会分割为两部分:返回给用户的 User chunk 、添加到 unsorted bin 中的 Remainder chunk。这一 Remainder chunk 就将成为 last remainder chunk。
那么引用局部性是如何达成的呢?
当用户的后续请求 small chunk,并且 last remainder chunk 是 unsorted bin 中唯一的 chunk,该 last remainder chunk 就将分割成两部分:返回给用户的 User chunk、添加到 unsorted bin 中的 Remainder chunk(也是 last remainder chunk)。因此后续的请求的 chunk 最终将被分配得彼此靠近。
TCache
tcache(per-thread cache)在glibc2.26中引入,进一步提升堆管理性能。
| |
tcache_entry用于链接空闲的chunk,指针直接指向chunk的userdata部分,也就是说复用了指针的含义。
每个arena都会维护一个tcache_prethread_struct,它是整个tcache机制的管理结构,其中包含TCACHE_MAX_BINS个tcache_entry链表。链入其中的chunk大小相同,所以通常也叫做tcache bin。其特性如下:
- 每个tcache bin最多只能有7个(
TCACHE_FILL_COUNT)chunk - tcache bin中chunk的inuse位不会置零,也就是说不会进行合并
- LIFO
可以看到其特性和fastbin是非常类似的。释放时在填满tcache之后才进入传统的释放过程,分配时也先从tcache中搜索。
tcache bin一共有64个(TCACHE_MAX_BINS),其大小范围为:
| |
由于tcache的增加和删除非常简洁,因此速度很快,但另一方面这也意味着缺乏各种安全检查和mitigation,在利用时候也格外方便。
commit添加了double free检测。